气候模型特征
…
模型数据特征
数据源:
比较框架
基于实验协议/方案的比较框架,协会官方规定实验的数据接口,实验参与者注册参与实验,专家审核,最后开放展示实验结果。
协议包括实验的细节,如CORDEX_ESD实验的协议包括:
- 预测因子:
- 数据源:ERA-I 1979-2013
- 变量:
- 空间分辨率:任何ERA-I的原生或后处理的空间分辨率
- 时间分辨率:任何ERA-I的原生或后处理的时间分辨率
- 其他预测因子:
- 预测值:
- CLARIS LPB 数据集的站点日数据
- Tmin, Tmax, Precipitation(pr)
- 时间范围:1979-2013
- 结果提交:
- NetCDF:满足附录表描述要求的文件
- 文本文件:和预测值数据相同格式的
- 实验环节:
- 分析和诊断:
统计对比方法
nc 数据的统计方法
指标:
- Bias (i.e. spatial grid of differences)
- Temporal Standard Deviation
- Standard Deviation Ratio
- Pattern Correlation
- Temporal Correlation
- Temporal Mean Bias
-
RMS Error (with mean computed over time and space)
- 统计降尺度:(缩小的未来)=(当前观察)+(当前模拟和未来模拟之间的平均差异)
比较流程:
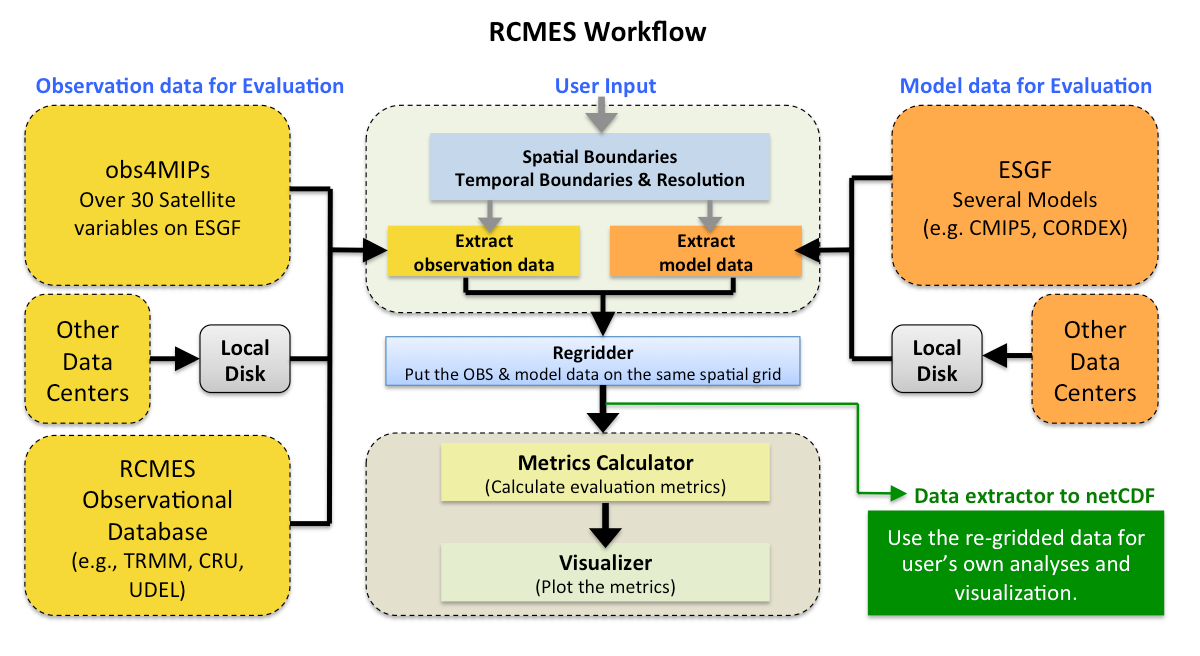
地区划分:
-
1. 模型模拟值和观测值两者的对比:
观测值等值线图 模拟等值线图 差异等值线图 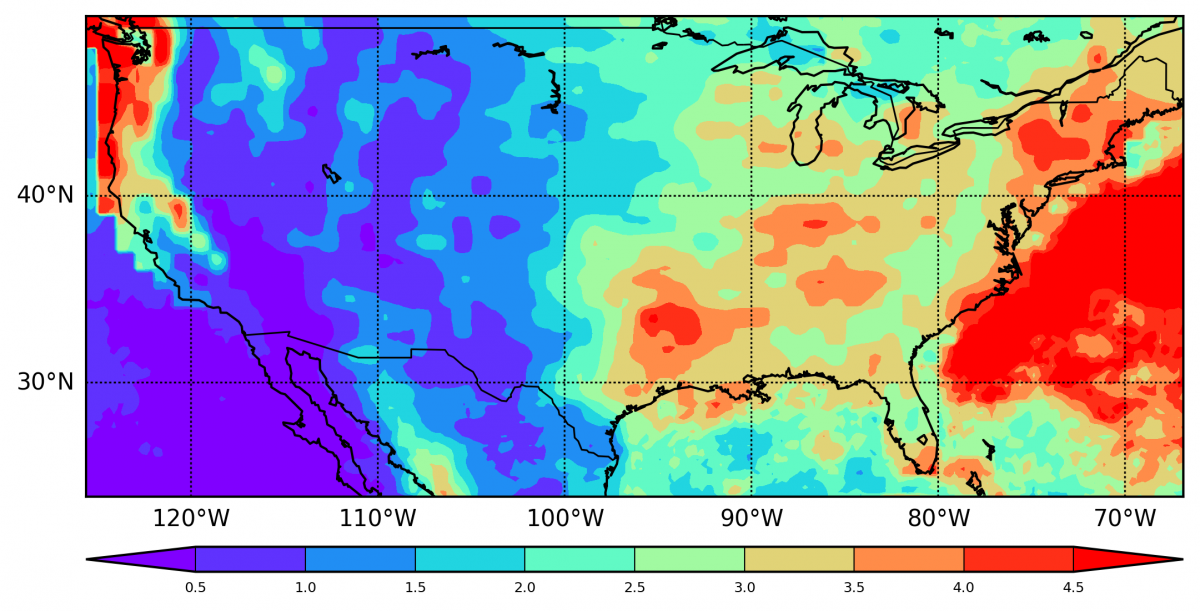
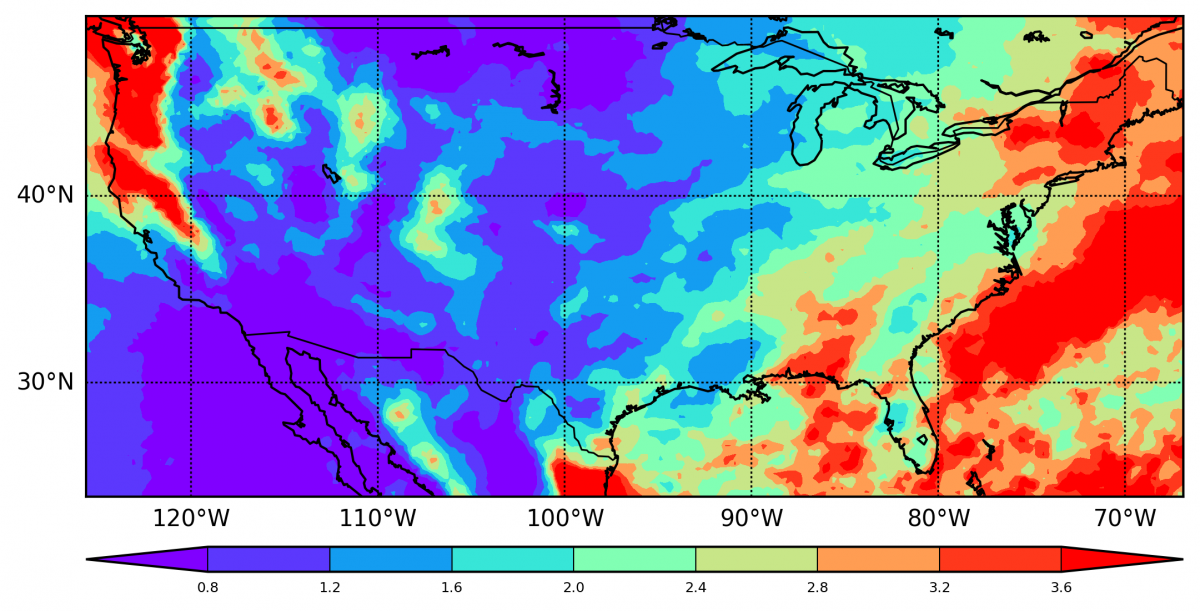
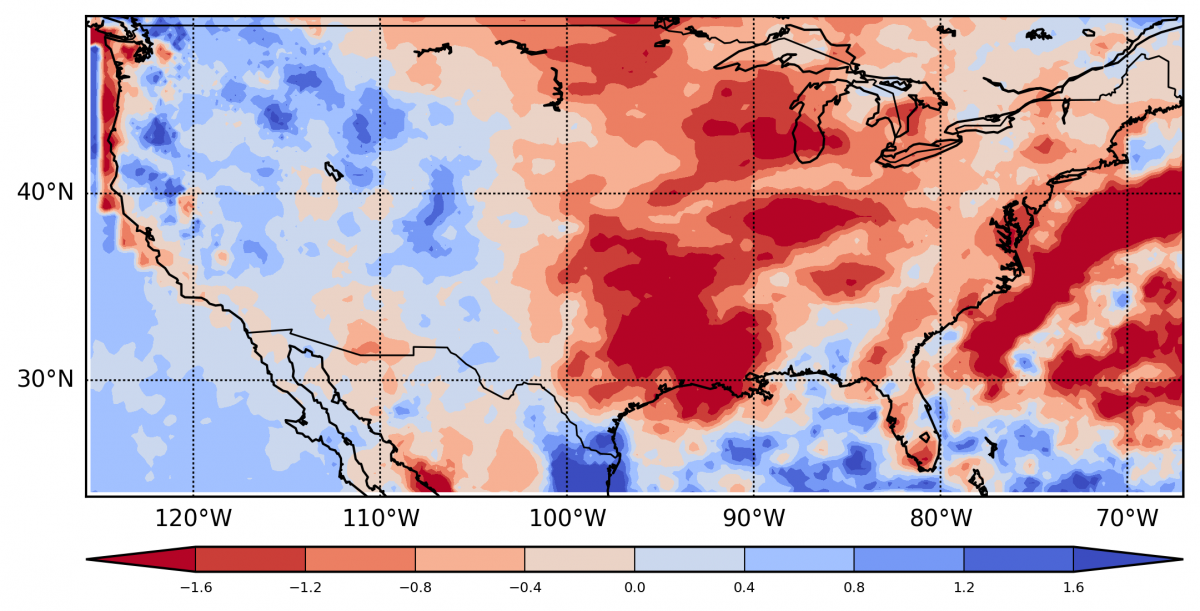
-
2. 各个模型与观测值的偏差比较,等值线图:
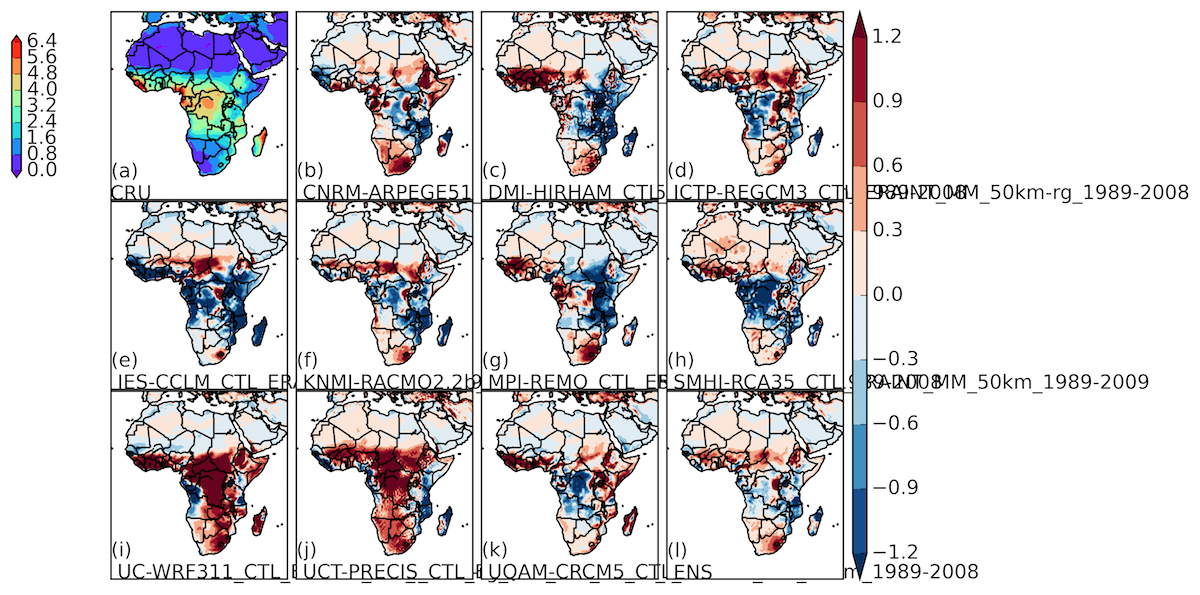
-
3. 泰勒图:泰勒图(Taylor,2001)常用于评价模型的精度,常用的精度指标有相关系数,标准差(STD)以及均方根误差(RMSE)。一般而言,泰勒图中的散点代表模型,辐射线代表相关系数,横纵轴代表标准差,而虚线代表均方根误差。泰勒图一改以往用散点图这种只能呈现两个指标来表示模型精度的情况。从更广义地来讲,泰勒图可以延展到需要用二维平面呈现三维数据的应用场景。这一点与三元图有异曲同工之妙。标准差和均方根误差的区别看这里
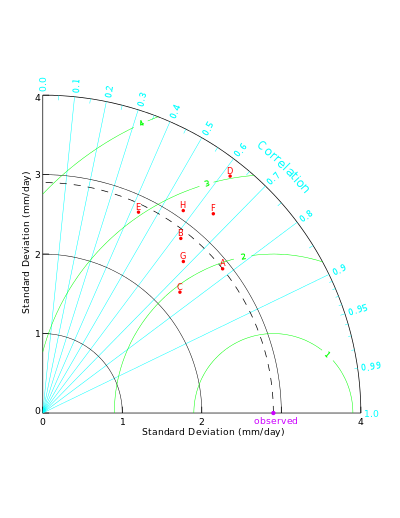
画法:
- standard deviation: [observation: number, ...simulations: number[]] - rmsd: [observation: 0, ...simulations: number[]] - coef: [observation: 1, ...simulations: number[]] - markerLabel: ['Non-Dimensional Observation', ...simulations: string[]] - tickRMS: np.arange[start, end, step] - tickSTD: np.arange[start, end, step] - tickCOR: np.concatenate((np.arange(0,1.0,0.2), [0.9, 0.95, 0.99, 1])) - rmslabelformat: ':.1f' -
4. 子区域的月度时间序列比较图:
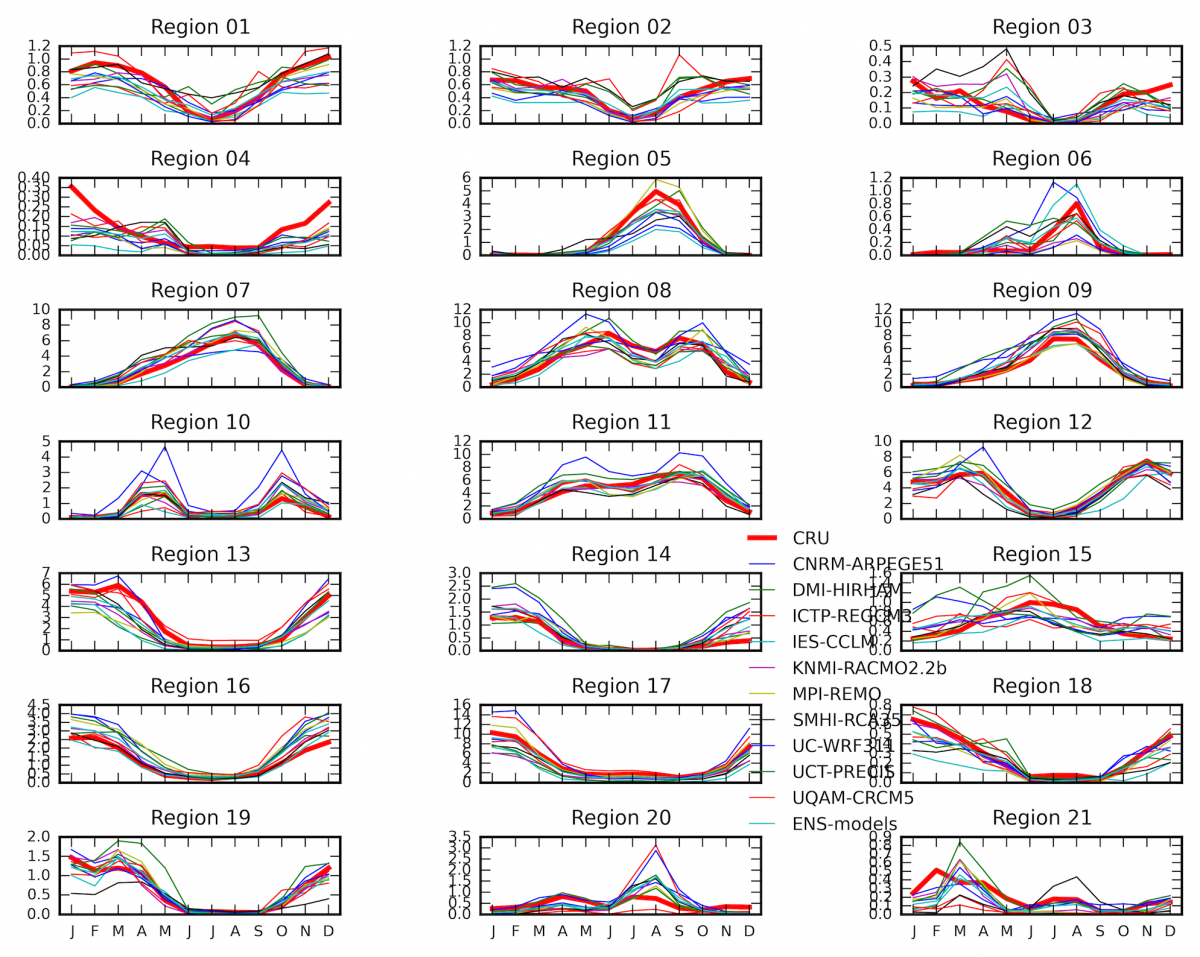
-
5. 不同地区的纵向图:对于定义的每个子区域和模型,显示偏差,标准偏差,相关性和RMSE。
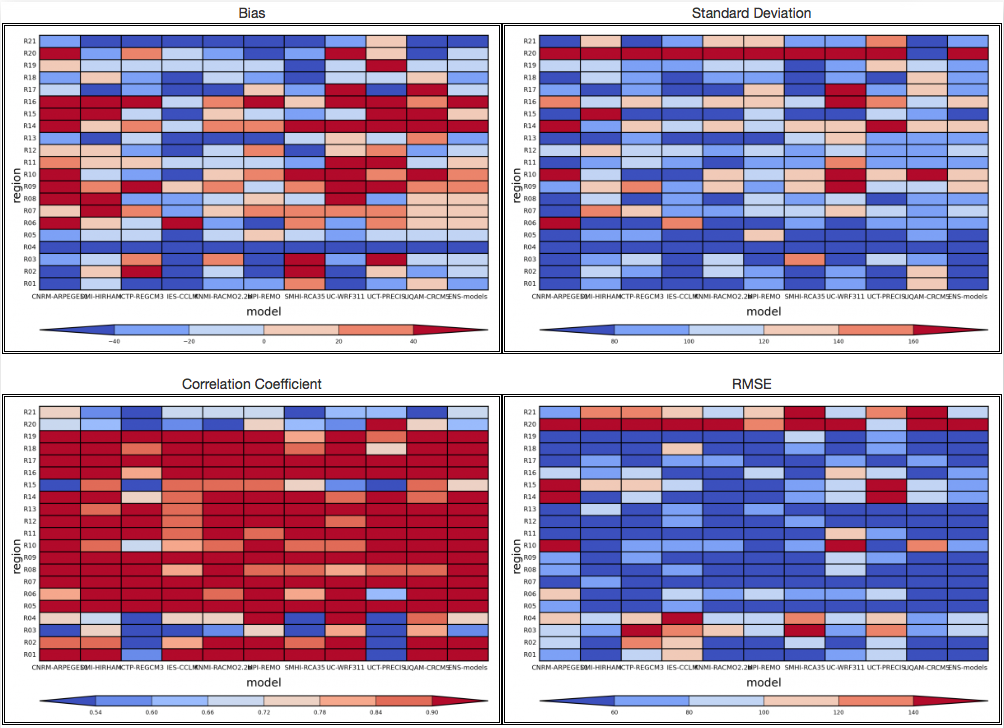
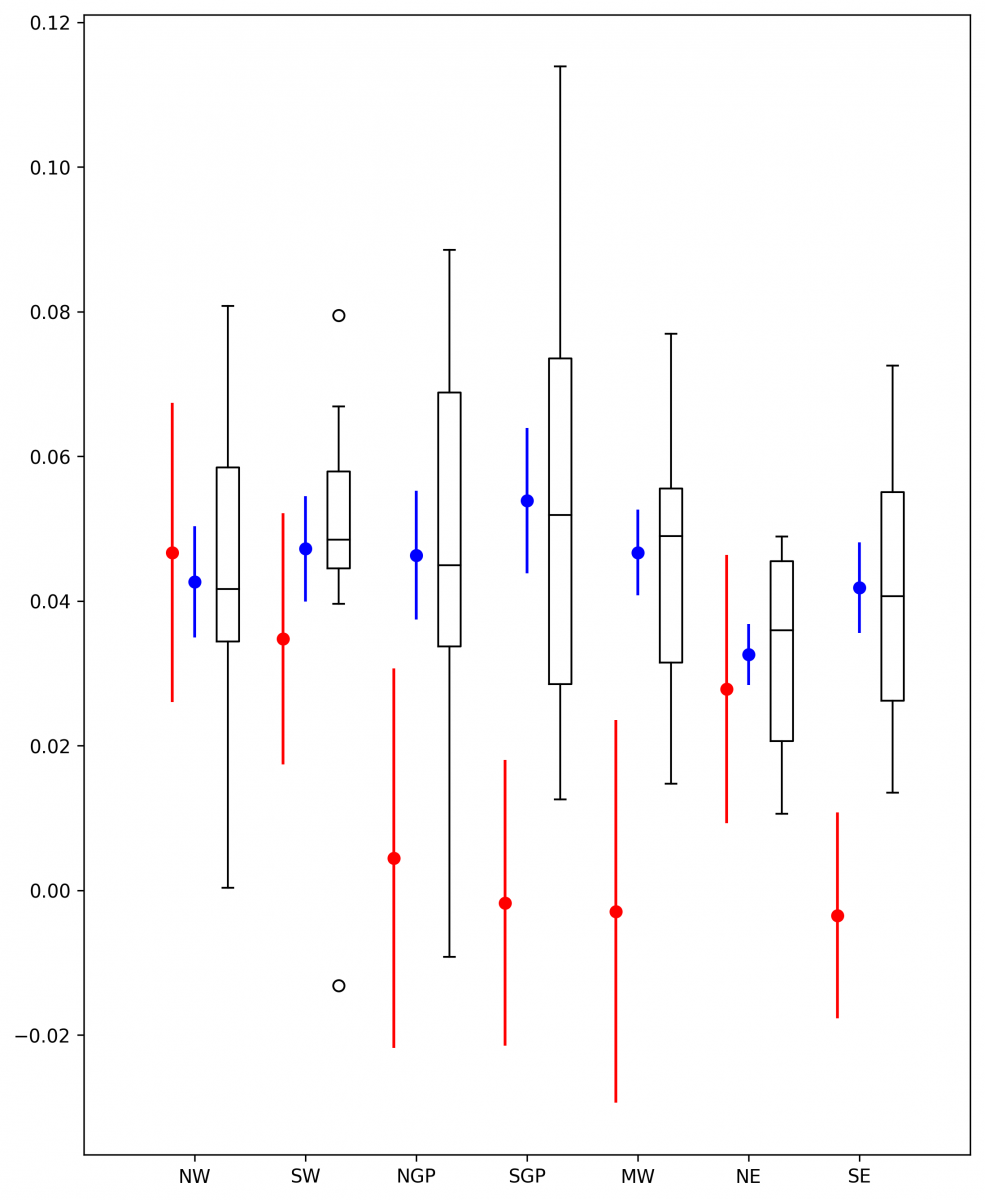
-
平均近地面气温十年趋势和观测标准误差(红色),自举多模式集合和标准误差(蓝色),以及JJA 1980-2005区域的单个模型模拟十年平均趋势的箱形图。参考
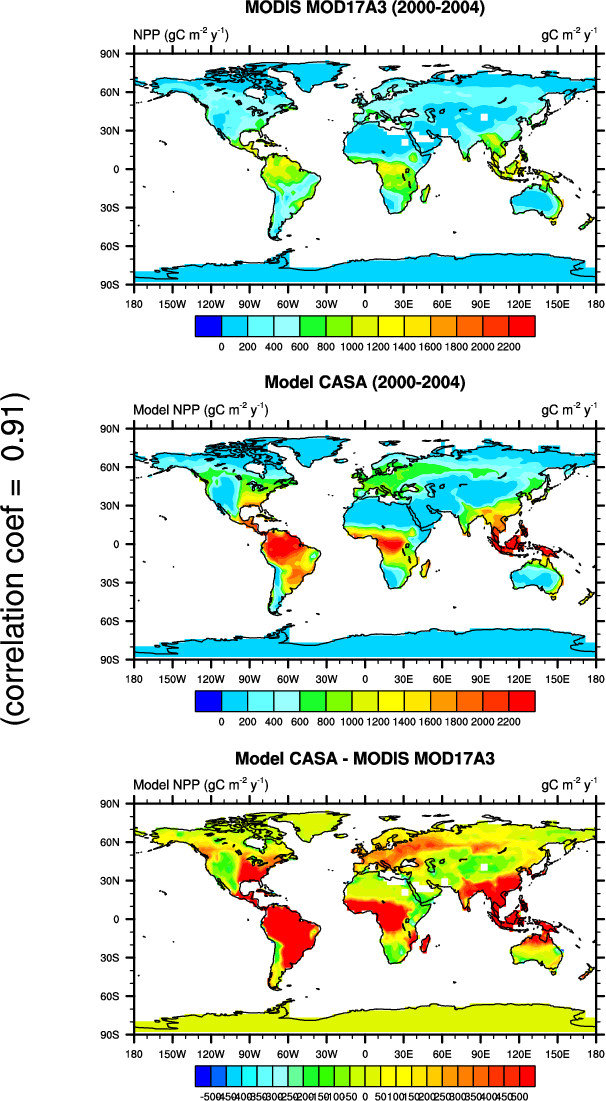
- 地图上叠加统计子图
- 散点图,
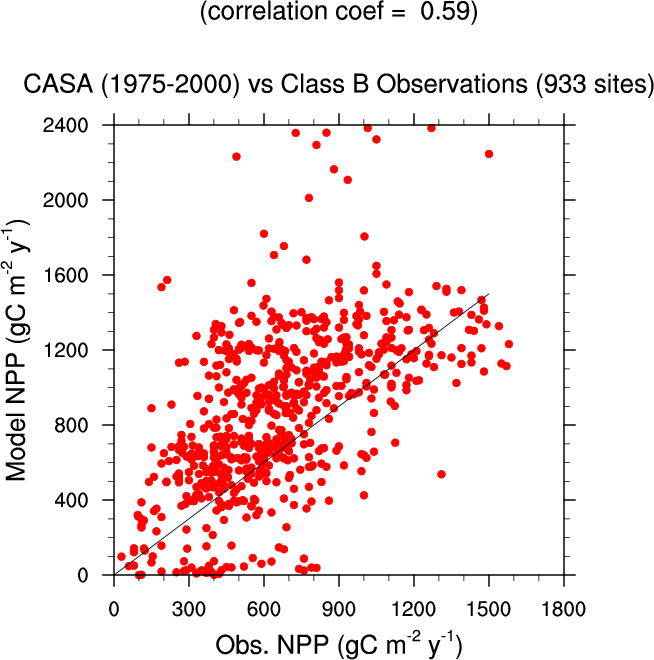
- 观测数据 MODIS MOD17A3/MOD15A2, CRUT3v, CN05
- table
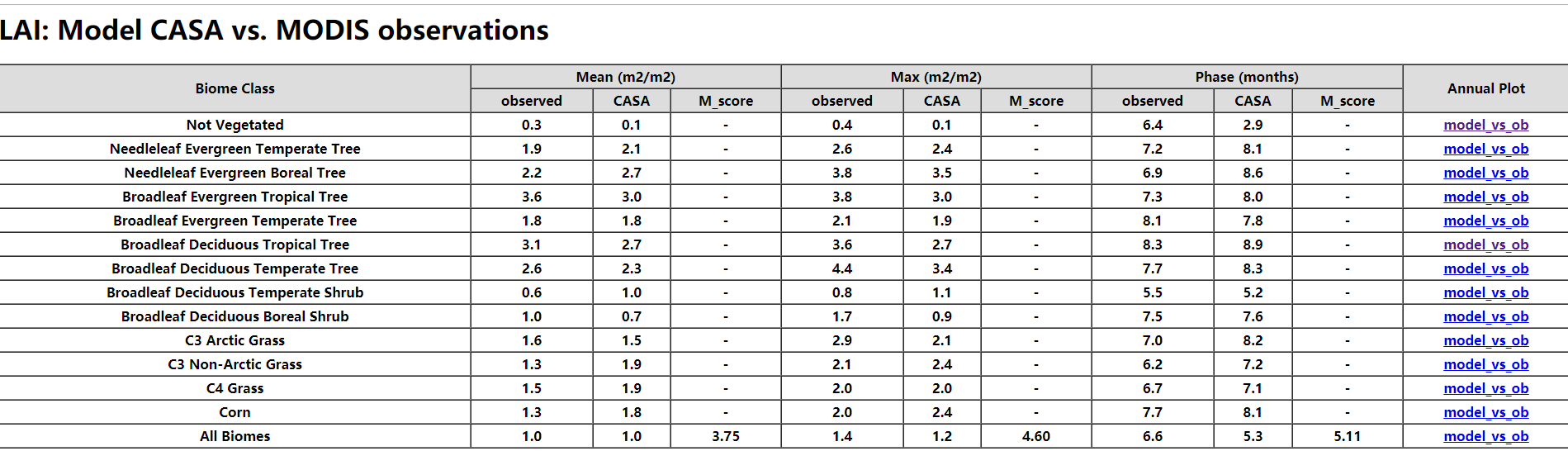
- 模型运行的细节都需要输出,包括 spin_up 时长,spin_up 结束得到的co2浓度
- 对比多个模型模拟的温度和降雨的关系
论文写作
- 用了什么数据集(观测数据、输入数据),选择什么时间范围、空间范围,以及那些模型进行对比。
- 对比的几个要素,比如温度、降水、NPP、GPP。
- 结论:模型模拟的差异性、一致性。研究区域的目标要素的发展趋势、空间分布、空间分异
几个亮点:
- 对比流程:
- 网络架构:
- 边缘计算:主动拉取计算任务、贡献计算能力
模拟情景
对比要素:
- 碳循环要素:GPP, NPP, NEP, Biomass, 生态系统呼吸
- 水循环要素:ET, 径流
参考案例
-
an end-to-end evaluation of CORDEX Africa regional climate models,下载文章
-
an end-to-end evaluation of North American Regional Climate Change Assessment Program ,下载 NASA Technical Report
-
a project to assess the credibility of dynamically-downscaled climate projections using the NASA Unified-WRF (NU-WRF), a version of WRF that integrates unique physics modules and capabilities developed at NASA, and the NASA GEOS-5 AGCM replay simulations,下载文章
table 数据的统计方法
- 时间序列折线图
- 统计指标
总结
关于模型运行
- 比较方法全部针对
(子)区域 - 所以,目前的难点是,收集一套可以用于IBIS、BIOME-BGC两者运行的
标准数据集,针对模型特点,将数据集重构成模型支持的数据格式,模型运行结束后再将结果重构为标准数据集格式。 - 对于以区域为单位运行的模型,直接调用
- 对于以点为单位运行的模型,将区域数据以格子为单元拆分,重构为输入数据,运行后再重构回去。这样两者具有可比性。
- 如果想以点为单位对比,则在从NetCDF中抽取数据对比。
关于标准数据集
- 标准数据集按模型专题组织,一个专题的模型使用同一套标准数据集。另外,标准数据集是
成套的,每套里有这个专题需要的各式各样的数据条目。比如模拟NPP的模型使用一套共同的数据集 - 一个专题的模型可以有多个标准数据集
- 其中,每一个标准数据集有一定的
时空分辨率,时空范围,可以是全球数据的子区域,不一定非得是全球数据。只要能够在一定区域内模拟就行 - 标准数据集不是模型运行的输入数据,后者得经过前者处理才能得到
关于比较方法
- 比较方法只和数据格式相关联
周边工具
- 可视化库
- 数据重构库
关于操作结果的缓存
- 数据转换结果的缓存:对于BIOME-BGC,标准数据集转换结果缓存起来,而且还要做转换前后数据的
映射查找表,能重用的地方重用。
实施
nc 数据的半自动化处理,发布
注意:所有程序均在 linux 平台运行
- 数据准备
- 全球站点数据驱动模型的运行
- nc 数据抽取
- 模拟结果的抽取
- 求与观测结果的偏差
- netcdf 数据服务的发布
- 数据实体的发布
- 样式的发布
- 图层的发布(允许时间维切片)
- 等值线图:前端请求和展现,数据的 url 和 _id 对应
- time dimension animation
- sub-region list
- bias map
- 泰勒图
- 折线图
- 纵向图