浏览器组成
用户界面:包括了地址栏、返回前进按钮、书签菜单等。在每一个请求页内,你都可以看到这些UI组件,除了主窗口。浏览器引擎:用来查询和操作渲染引擎的接口渲染引擎:负责渲染请求的内容。比如,若果请求的资源是html文件,那么渲染引擎负责解析html以及css,然后再把结果渲染到页面。网络连接:用于处理网络请求,如http请求。它不依赖不同的平台,这意味着它可以在不同平台工作。UI后台:用于渲染基础部件,如多选框、窗口等。它暴露了一个不是特定平台的通用接口,在底层调用了操作系统的用户接口。js引擎:用于解析javascript代码数据存储:这是一个持久层。浏览器需要在硬盘中存储各式数据,比如cookie。HTML5定义了‘web database’这样轻量级的web浏览器存储技术。
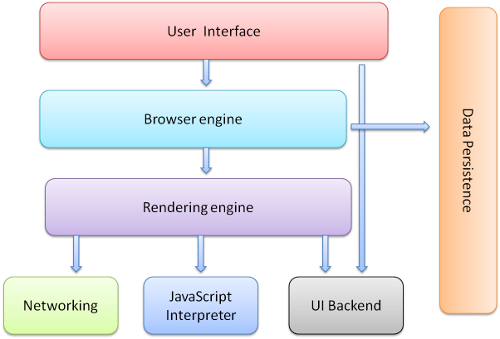
在 chrome 中,每个 tab 是一个单独的进程,这样多个tab之间不相互影响。在每个tab进程下,浏览器通常有以下常驻线程:
- GUI 渲染线程
- Js 引擎线程
- 定时器线程
- 异步事件队列线程
- http 请求线程
资源下载
- 多个 css 下载可以同时开始,先加载完的先解析
- 没有 defer 和 async 标签时,多个 js 的加载顺序是按照顺序的,加载完执行时会阻塞 css 解析和 dom 解析
- 浏览器的http连接并发限制:同域下最大8个。对应的性能优化手段叫 cookie free 和 domain hash
link vs @import:
- link是XHTML标签,除了加载CSS外,还可以定义RSS等其他事务;@import属于CSS范畴,只能加载CSS。
- link引用CSS时,在页面载入时同时加载;@import需要页面网页完全载入以后加载。
- link无兼容问题;@import是在CSS2.1提出的,低版本的浏览器不支持。
- link标签支持使用Javascript控制DOM去改变样式;而@import不支持。
渲染流程
webkit 和 gecko 的渲染流程有细微的区别,其实是名字不一样,负责的内容大致都是一样的:
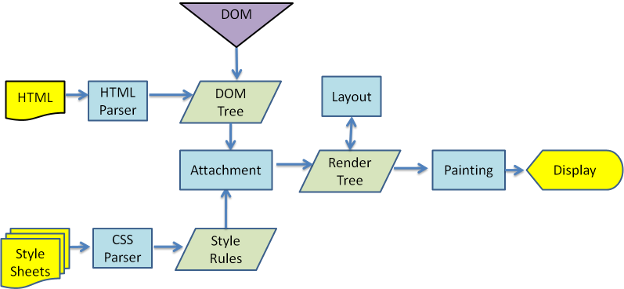
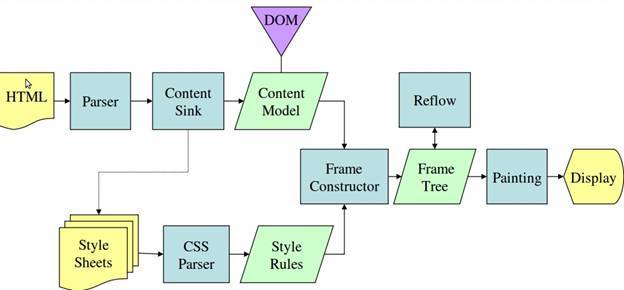
JS, CSS, DOM 加载解析的关系
- JS, CSS, img, 等外部资源是并行下载的
- JS会修改DOM,遇到JS标签时,会阻塞后续DOM的解析,
- 由于JS需要查询CSS信息,JS前面的CSS加载和CSSOM的构建也会阻塞JS的加载和执行。给JS添加 async 标签可以解除这种阻塞关系。
- 阻塞关系:CSS阻塞JS,JS阻塞DOM;在没有JS时,CSS和DOM的加载和解析是并行的
repaint
从根节点递归调用,计算每一个元素的大小、位置等,给每个节点所应该出现在屏幕上的精确坐标。
reflow
遍历渲染树,每个节点将使用UI后端层来绘制。
性能优化
Reflow 的成本比 Repaint 的成本高得多的多。DOM Tree 里的每个结点都会有 reflow 方法,一个结点的 reflow 很有可能导致子结点,甚至父点以及同级结点的 reflow。
以下操作都会引起 repaint 或 reflow:
- 修改 DOM
- 移动 DOM 的盒子模型和定位相关属性
- 添加动画
- 修改 CSS 样式
- window.resize, scroll
- 修改字体
所以,优化时尽量减少以上操作,建议:
- 将多个 css 操作合并
- position 的 top, left 会引起 reflow,但是 transform 下的 translate 并不会,其他 transform 属性也会减少 reflow
- 使用 flex 代替 table 布局
- 降低选择器的复杂度
- throttle, debounce
参考
- 浏览器工作过程详解(译)一
- 浏览器工作过程详解(译)二
- 网页渲染性能优化
- 性能:深入理解浏览器渲染原理 reflow & repaint
- 前端性能优化(CSS动画篇)
- 浅析浏览器渲染原理
- 分析关键渲染路径性能